mobile_rag_engine 0.5.0  mobile_rag_engine: ^0.5.0 copied to clipboard
mobile_rag_engine: ^0.5.0 copied to clipboard
A high-performance, on-device RAG (Retrieval-Augmented Generation) engine for Flutter. Run semantic search completely offline on iOS and Android with HNSW vector indexing.
Mobile RAG Engine #

![]()
Production-ready, fully local RAG (Retrieval-Augmented Generation) engine for Flutter.
Powered by a Rust core, it delivers lightning-fast vector search and embedding generation directly on the device. No servers, no API costs, no latency.
Why this package? #
No Rust Installation Required #
You do NOT need to install Rust, Cargo, or Android NDK.
This package includes pre-compiled binaries for iOS, Android, and macOS. Just pub add and run.
Performance #
| Feature | Pure Dart | Mobile RAG Engine (Rust) |
|---|---|---|
| Tokenization | Slow | 10x Faster (HuggingFace tokenizers) |
| Vector Search | O(n) | O(log n) (HNSW Index) |
| Memory Usage | High | Optimized (Zero-copy FFI) |
100% Offline & Private #
Data never leaves the user's device. Perfect for privacy-focused apps (journals, secure chats, enterprise tools).
Features #
- Cross-Platform: Works seamlessly on iOS, Android, and macOS
- HNSW Vector Index: Fast approximate nearest neighbor search (proven scale up to 10k+ docs)
- Hybrid Search Ready: Supports semantic search combined with exact matching
- Markdown Structure-Aware Chunking: Preserves headers, code blocks, and tables during chunking with header path inheritance
- PDF/DOCX Text Extraction: Built-in document parsing with smart dehyphenation and page number removal
- Auto-Chunking: Intelligent text splitting strategies included (Unicode-based semantic chunking)
- Model Flexibility: Use standard ONNX models (e.g.,
bge-m3,all-MiniLM-L6-v2)
Benchmark Results #
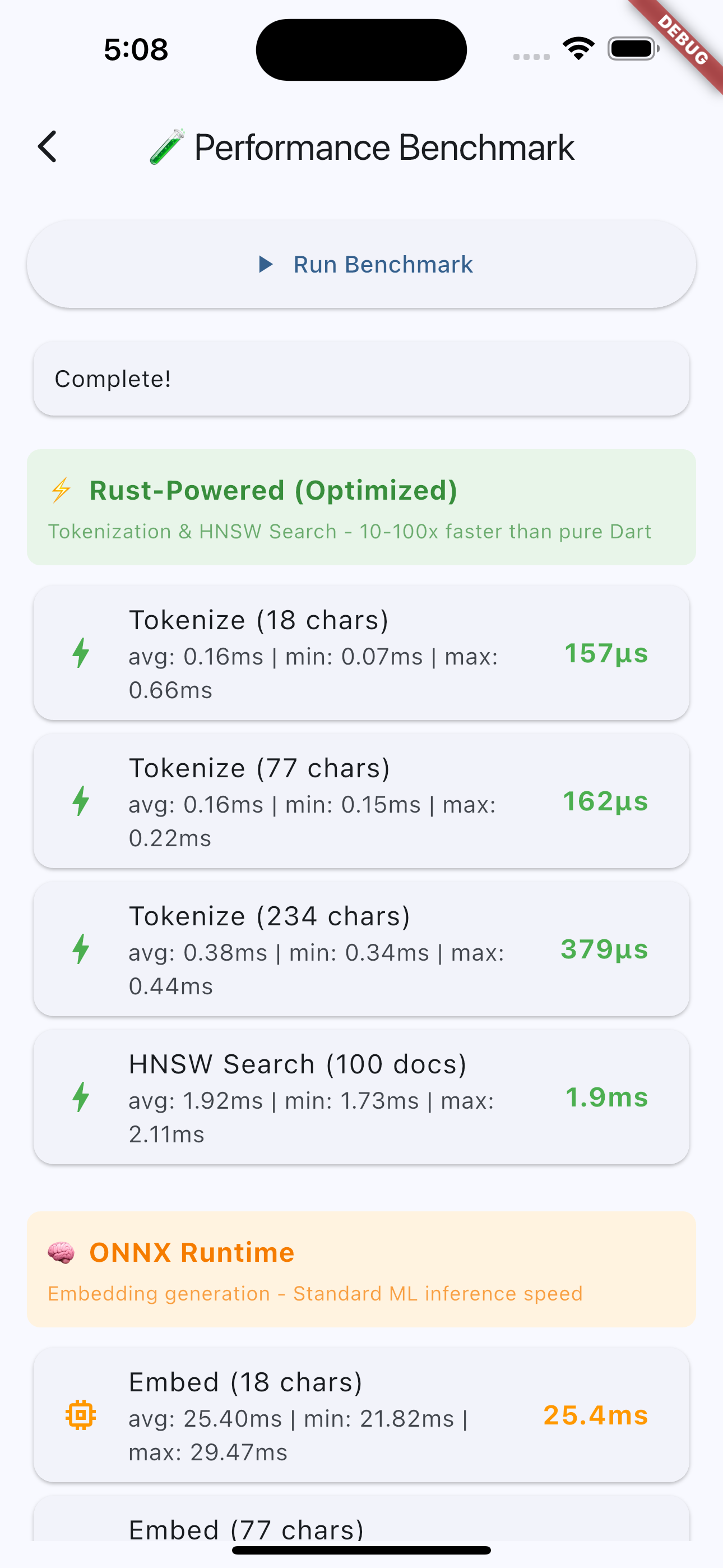
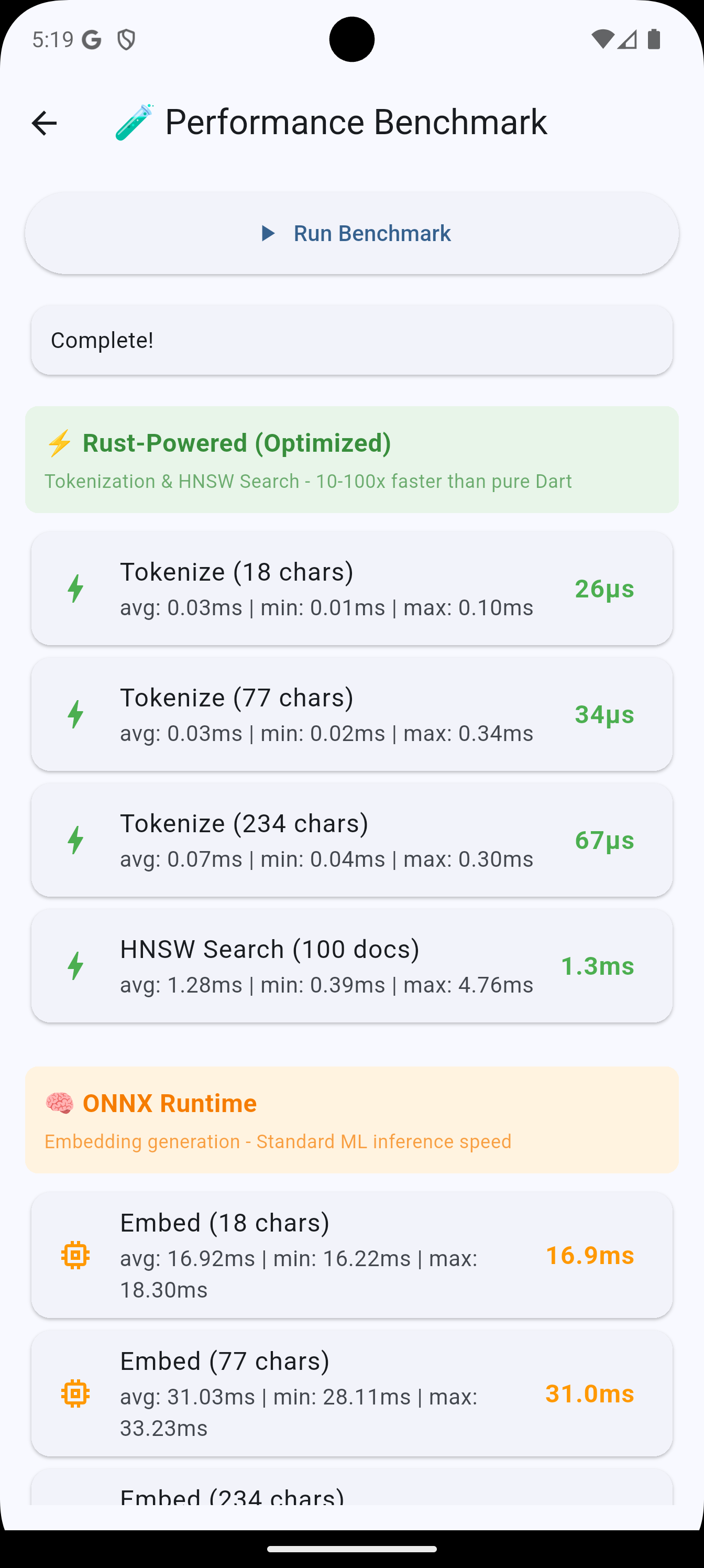
Requirements #
| Platform | Minimum Version |
|---|---|
| iOS | 13.0+ |
| Android | API 21+ (Android 5.0 Lollipop) |
| macOS | 10.15+ (Catalina) |
ONNX Runtime is bundled automatically via the
onnxruntimeplugin. No additional native setup required.
Installation #
1. Add the dependency #
dependencies:
mobile_rag_engine: ^0.4.3
2. Download Model Files #
# Create assets folder
mkdir -p assets && cd assets
# Download BGE-m3 model (INT8 quantized, multilingual)
curl -L -o model.onnx "https://huggingface.co/Teradata/bge-m3/resolve/main/onnx/model_int8.onnx"
curl -L -o tokenizer.json "https://huggingface.co/BAAI/bge-m3/resolve/main/tokenizer.json"
See Model Setup Guide for alternative models and production deployment strategies.
Quick Start #
Initialize the engine and start searching in just a few lines of code:
import 'package:mobile_rag_engine/mobile_rag_engine.dart';
void main() async {
// 1. Initialize (just 3 lines!)
await RustLib.init();
final rag = await RagEngine.initialize(
config: RagConfig.fromAssets(
tokenizerAsset: 'assets/tokenizer.json',
modelAsset: 'assets/model.onnx',
),
);
// 2. Add Documents (auto-chunked & embedded)
await rag.addDocument('Flutter is a UI toolkit for building apps.');
await rag.rebuildIndex();
// 3. Search with LLM-ready context
final result = await rag.search('What is Flutter?', tokenBudget: 2000);
print(result.context.text); // Ready to send to LLM
// Optional: Format as prompt
final prompt = rag.formatPrompt('What is Flutter?', result);
}
Advanced Usage: For fine-grained control, you can still use the low-level APIs (
initTokenizer,EmbeddingService,SourceRagService) directly. See the API Reference.
PDF/DOCX Import #
Extract text from documents and add to RAG:
import 'dart:io';
import 'package:file_picker/file_picker.dart';
import 'package:mobile_rag_engine/mobile_rag_engine.dart';
Future<void> importDocument(RagEngine rag) async {
// Pick file
final result = await FilePicker.platform.pickFiles(
type: FileType.custom,
allowedExtensions: ['pdf', 'docx'],
);
if (result == null) return;
// Extract text (handles hyphenation, page numbers automatically)
final bytes = await File(result.files.single.path!).readAsBytes();
final text = await extractTextFromDocument(fileBytes: bytes.toList());
// Add to RAG with auto-chunking
await rag.addDocument(text, filePath: result.files.single.path);
await rag.rebuildIndex();
}
Note:
file_pickeris optional. You can obtain file bytes from any source (network, camera, etc.) and pass toextractTextFromDocument().
Benchmarks #
Rust-powered components (M3 Pro macOS):
| Operation | Time | Notes |
|---|---|---|
| Tokenization (234 chars) | 0.04ms | HuggingFace tokenizers crate |
| HNSW Search (100 docs) | 0.3ms | instant-distance (O(log n)) |
These are the components where Rust provides 10-100x speedup over pure Dart implementations.
Embedding generation uses ONNX Runtime (platform-dependent, typically 25-100ms per text).
Architecture #
This package bridges the best of two worlds: Flutter for UI and Rust for heavy lifting.
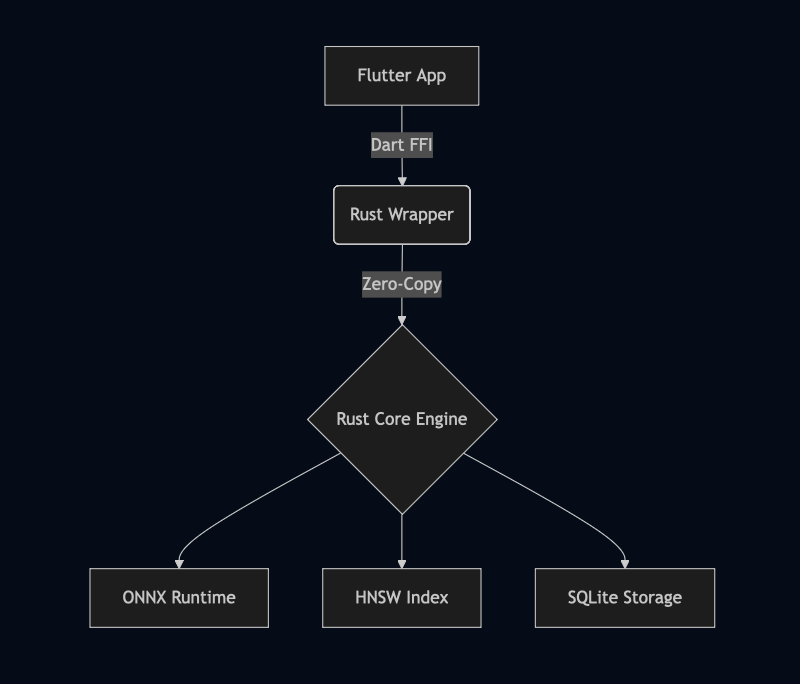
| Component | Technology |
|---|---|
| Embedding | ONNX Runtime with quantized models (INT8) |
| Storage | SQLite for metadata + memory-mapped vector index |
| Search | instant-distance (HNSW) for low-latency retrieval |
| Tokenization | HuggingFace tokenizers crate |
Model Options #
| Model | Dimensions | Size | Max Tokens | Languages |
|---|---|---|---|---|
| Teradata/bge-m3 (INT8) | 1024 | ~542 MB | 8,194 | 100+ (multilingual) |
| all-MiniLM-L6-v2 | 384 | ~25 MB | 256 | English only |
Important: The embedding dimension must be consistent across all documents. Switching models requires re-embedding your entire corpus.
Custom Models: Export any Sentence Transformer to ONNX:
pip install optimum[exporters]
optimum-cli export onnx --model sentence-transformers/YOUR_MODEL ./output
See Model Setup Guide for deployment strategies and troubleshooting.
Documentation #
| Guide | Description |
|---|---|
| Quick Start | Get started in 5 minutes |
| Model Setup | Model selection, download, deployment strategies |
| FAQ | Frequently asked questions |
| Troubleshooting | Problem solving guide |
Contributing #
Bug reports, feature requests, and PRs are all welcome!
License #
This project is licensed under the MIT License.
Metadata
Publisher
Weekly Downloads
Metadata
A high-performance, on-device RAG (Retrieval-Augmented Generation) engine for Flutter. Run semantic search completely offline on iOS and Android with HNSW vector indexing.
Repository (GitHub)
View/report issues
Topics
#ai #machine-learning #semantic-search #vector-database #rag
Documentation
License
![]() MIT (license)
MIT (license)
Dependencies
flutter, flutter_rust_bridge, freezed_annotation, onnxruntime, path_provider, rag_engine_flutter