mobile_rag_engine 0.11.0  mobile_rag_engine: ^0.11.0 copied to clipboard
mobile_rag_engine: ^0.11.0 copied to clipboard
A high-performance, on-device RAG (Retrieval-Augmented Generation) engine for Flutter. Run semantic search completely offline on iOS and Android with HNSW vector indexing.
mobile_rag_engine #

![]()
- Build AI apps that understand user documents — fully on device.
- On-device knowledge runtime for Flutter AI apps.
- Bring document memory to your app — fully offline.
Turn PDFs, DOCX, Markdown and text files into a searchable knowledge assistant. No servers. No data upload. No embedding API required.
[document_rag_demo]
What you can build #
- 📄 Contract / insurance analyzer
- 🧠 Personal knowledge assistant
- 🏢 Offline company document search
- 📝 AI notes that remember user files
- ⚡ On-device AI cache layer for LLM apps
Quick Start (30 sec) #
// 1. Initialize
await MobileRag.initialize(
tokenizerAsset: 'assets/tokenizer.json',
modelAsset: 'assets/model.onnx',
);
// 2. Add Document
await MobileRag.instance.addDocument(
'LONG CONTRACT TEXT...', // Or extract from PDF
filePath: 'contract.pdf',
);
// 3. Search
// Returns context ready for LLM
final result = await MobileRag.instance.search(
'What is the cancellation policy?',
);
print(result.context.text);
Real Apps Built With mobile_rag_engine #
Contract Analyzer (Mobile) #
Scan long agreements and instantly extract key clauses. [contract_demo]
Local AI Chat (Desktop, Gemma) #
Chat with your documents fully offline. [chat_demo]
Works Offline #
Airplane mode — still answers. [offline_demo]
What is mobile_rag_engine? #
mobile_rag_engine is not a chatbot framework.
It is a local knowledge runtime for AI applications.
- Your app keeps the data.
- The model adapts to it.
Architecture #
graph TD
Flutter[Flutter App] --> Rust[Rust Runtime FFI]
Rust --> Pipeline[Embedding + Chunking + Vector Search]
Pipeline --> LLM[Local or External LLM]
Installation #
Add dependency:
dependencies:
mobile_rag_engine: ^1.0.0
Download embedding model:
mkdir -p assets && cd assets
# Download BGE-m3 model (INT8 quantized, multilingual)
curl -L -o model.onnx "https://huggingface.co/Teradata/bge-m3/resolve/main/onnx/model_int8.onnx"
curl -L -o tokenizer.json "https://huggingface.co/BAAI/bge-m3/resolve/main/tokenizer.json"
Detailed Usage #
Initialization #
Initialize once in main():
await MobileRag.initialize(
tokenizerAsset: 'assets/tokenizer.json',
modelAsset: 'assets/model.onnx',
);
Add Documents #
// Simple text
await MobileRag.instance.addDocument(
"Flutter is Google's UI toolkit...",
filePath: "file.txt"
);
// Extract from PDF (using built-in helper)
// final text = await extractTextFromDocument(fileBytes: bytes);
// await MobileRag.instance.addDocument(text);
Search #
Retrieve relevant context for your LLM:
final result = await MobileRag.instance.search(
"Explain cancellation conditions",
tokenBudget: 2000, // Fit within LLM context window
);
print(result.context.text);
Documentation #
- Adjacent Chunk Retrieval - Fetch surrounding context.
- Index Management - Stats, persistence, and recovery.
- Markdown Chunker - Structure-aware text splitting.
- Prompt Compression - Reduce token usage.
- Search by Source - Filter results by document.
- Search Strategies - Tune ranking and retrieval.
- Model Setup Guide - Choosing and downloading models.
- FAQ - Common questions.
Features #
| Category | Features |
|---|---|
| Document Input | PDF, DOCX, Markdown, Text |
| Chunking | Semantic + structured aware |
| Search | Hybrid BM25 + HNSW (Reciprocal Rank Fusion) |
| Storage | Persistent SQLite index |
| Performance | Rust core, zero-copy FFI |
| Context | Token budget + expansion window |
Performance #
| Feature | Pure Dart | mobile_rag_engine |
|---|---|---|
| Tokenization | Slow | 10x Faster |
| Vector Search | O(n) | O(log n) |
| Memory | High | Optimized |
Sample App #
Desktop reference implementation with local LLM:
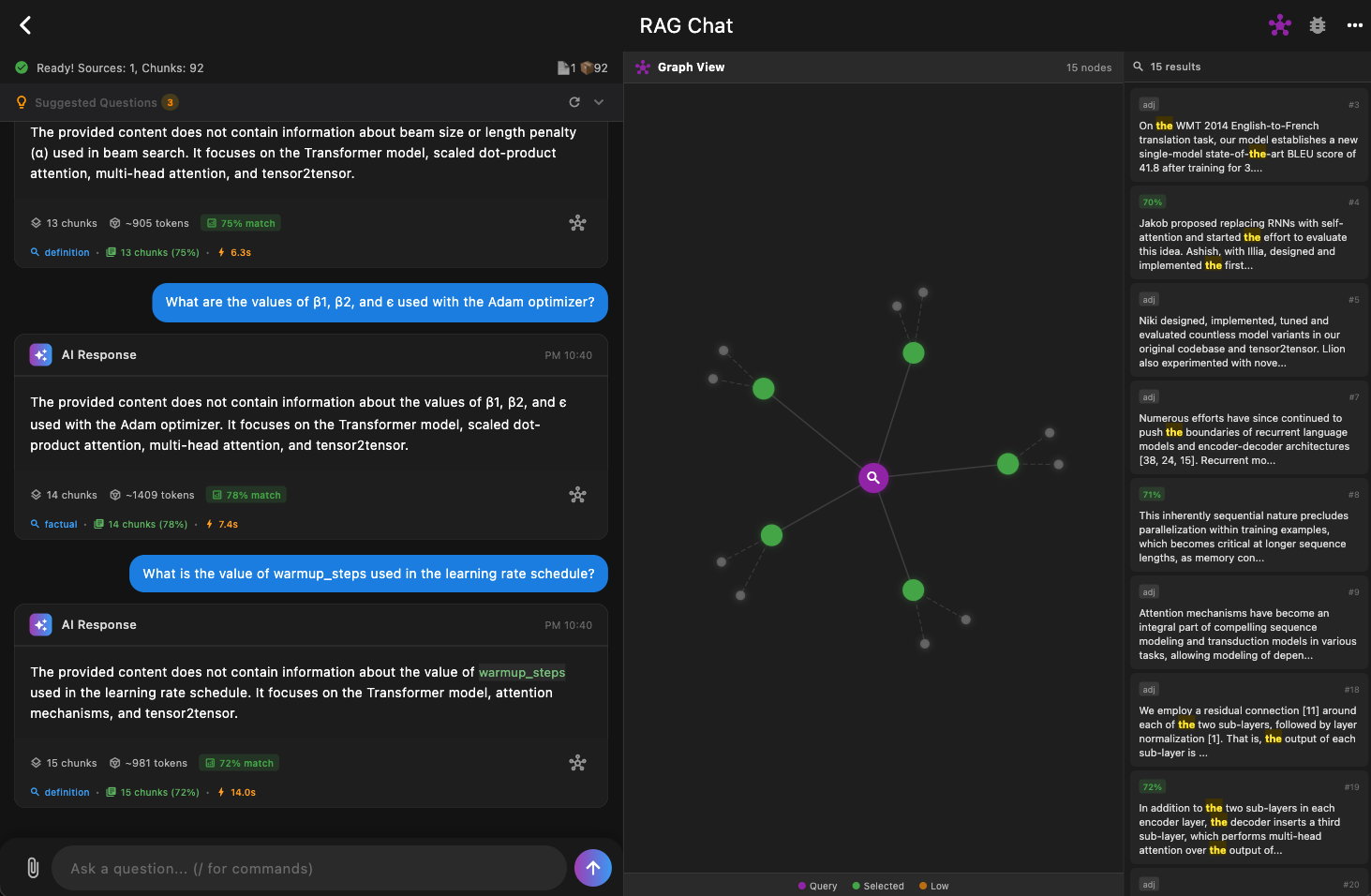
Contributing #
PRs and ideas welcome!
License #
MIT
Metadata
Publisher
Weekly Downloads
Metadata
A high-performance, on-device RAG (Retrieval-Augmented Generation) engine for Flutter. Run semantic search completely offline on iOS and Android with HNSW vector indexing.
Repository (GitHub)
View/report issues
Topics
#llm #machine-learning #semantic-search #vector-database #rag
License
![]() unknown (license)
unknown (license)
Dependencies
flutter, flutter_rust_bridge, freezed_annotation, onnxruntime, path_provider, rag_engine_flutter